Dolly Zooming - A Sense of Vertigo
by Barnaby Smith
“Dolly zoom” is a cinematography term for a method you'll instantly recognise. Originally pioneered by Irmin Roberts, a Paramount Pictures cameraman, the method was made famous by its memorable use by Alfred Hitchcock for the film Vertigo. The cinema device has made numerous appearances since and is usually used for giving a sense of vertigo, unease or depicting the emotional impact of a realisation on a character. The basic premise is to keep the subject of the frame at the same scale while changing the scale of the background and/or foreground. This effect can be extremely good at giving a sense of vertigo and unreality.
Dolly zooming can be achieved by changing the field of view while changing the distance from the subject to ensure the subject remains approximately the same desired scale. When using an actual camera, this would be achieved by using a zoom lens (zoom lenses change the focal length and thus field of view) and at the same time physically moving backwards of forwards as appropriate.
Because of the non-linear relationship between the field of view and camera distance required to achieve this effect, it takes a good degree of experience and skill to do manually. In computer graphics, however we can use an equation to help us out. A common equation to achieve this effect is:
Dolly zooming can be achieved by changing the field of view while changing the distance from the subject to ensure the subject remains approximately the same desired scale. When using an actual camera, this would be achieved by using a zoom lens (zoom lenses change the focal length and thus field of view) and at the same time physically moving backwards of forwards as appropriate.
Because of the non-linear relationship between the field of view and camera distance required to achieve this effect, it takes a good degree of experience and skill to do manually. In computer graphics, however we can use an equation to help us out. A common equation to achieve this effect is:
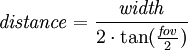
Now looking at the equation above, there are three variables. The field of view, which we can control and is therefore an input. The distance, which is calculated by the equation and is therefore the output. And finally, width which is a value relating to the target of our dolly zoom, this we will need to calculate ourselves. Fortunately this is straightforward as all we need do is multiply the target distance by the arctan of 90 degrees.
Assuming your camera view matrix is created using the standard Matrix.CreateLookAt() method, all you need adjust here is the camera eye position parameter. And assuming that the camera projection matrix is created using Matrix.CreatePerspectiveFieldOfView(), you can simply supply the field of view of the camera in radians.
Please note, this is the first time I have attempted to implement the effect so if the implementation can be improved I'd be delighted to hear how.
References
http://en.wikipedia.org/wiki/Dolly_zoom
http://www.gamedev.net/community/forums/topic.asp?topic_id=528056
http://www.mediacollege.com/video/shots/dolly-zoom.html
Assuming your camera view matrix is created using the standard Matrix.CreateLookAt() method, all you need adjust here is the camera eye position parameter. And assuming that the camera projection matrix is created using Matrix.CreatePerspectiveFieldOfView(), you can simply supply the field of view of the camera in radians.
Please note, this is the first time I have attempted to implement the effect so if the implementation can be improved I'd be delighted to hear how.
References
http://en.wikipedia.org/wiki/Dolly_zoom
http://www.gamedev.net/community/forums/topic.asp?topic_id=528056
http://www.mediacollege.com/video/shots/dolly-zoom.html
